Your organization already knows the answer. It’s in a document somewhere, a policy file, a research archive, a clinical guideline or a course manual. The problem is that nobody can find it fast enough to matter. Traditional search systems never fully solved this problem.
Then came AI. And with it, a genuine fix. Large language models (LLMs) are transforming how organizations access and use information. Not a better way to search, but a smarter way to retrieve, understand, and respond. It’s called Retrieval-Augmented Generation, and it may be the most practically useful AI development your organization hasn’t fully acted on yet.
What Is Retrieval-Augmented Generation (RAG)?
RAG stands for Retrieval-Augmented Generation. Let’s break that down into plain English:
- Retrieval — The system looks up relevant information from your documents, databases, or knowledge sources.
- Augmented — That retrieved information is added to the AI’s prompt, enriching what it knows before it responds.
- Generation — The AI then generates a response that’s grounded in the actual information it just looked up.
Without RAG, AI relies only on its training data, which can be outdated or inaccurate.
Why AI models Need Retrieval-Augmented Generation?
AI models on their own have four significant limitations. Here’s what they are and how RAG fixes them:
| AI Limitation | Business Impact | How RAG Solves It |
| AI hallucinations | AI can generate responses that sound convincing but are factually incorrect, creating risks in compliance, customer support, and decision-making. | RAG retrieves information from trusted sources before generating responses, improving accuracy and reducing fabricated answers. |
| Static knowledge | AI models cannot automatically access recent policies, product updates, or regulatory changes. | RAG retrieves current information from updated knowledge bases without requiring expensive model retraining. |
| Lack of business context | Public AI models do not understand internal workflows, policies, or organizational knowledge. | RAG connects AI systems to internal data sources, making company knowledge accessible through a conversational interface. |
| Information overload | Processing large volumes of content directly inside AI models can increase costs and reduce response quality | RAG retrieves only the most relevant information for each query, improving efficiency and scalability. |
| Limited transparency | Users may not know where AI-generated answers come from, making verification difficult. | RAG systems can reference source documents, making responses more transparent, trustworthy, and auditable. |
| High maintenance costs | Traditional AI customization methods can be expensive and time-consuming to maintain. | RAG allows organizations to update knowledge by changing documents instead of retraining models. |
Key Takeaway: RAG doesn’t just make AI smarter, it makes AI useful for real business operations where accuracy, currency, and accountability matter.
How Retrieval-Augmented Generation Works
You don’t need to understand technical plumbing to appreciate how RAG works.
The diagram below illustrates a typical RAG pipeline in two main phases: a knowledge base (a one-time setup) and a real-time retrieval and generation layer.
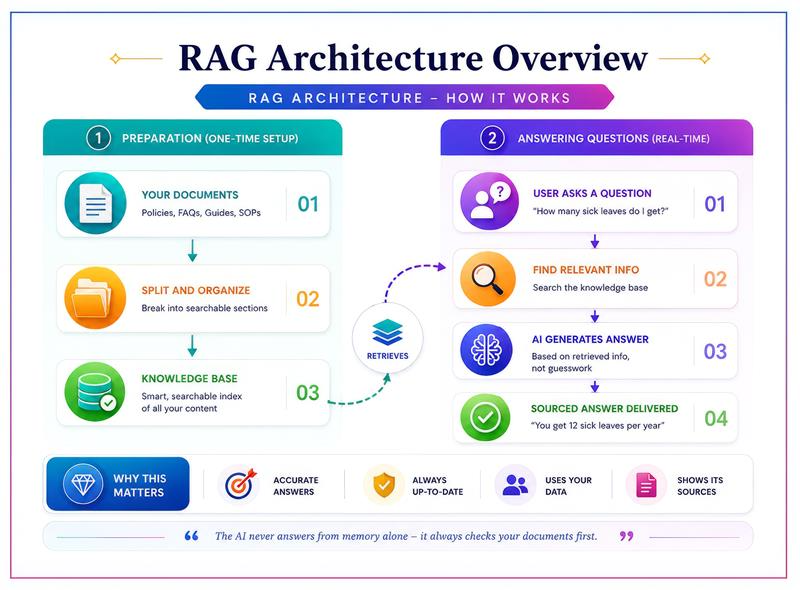
The Left Side: Preparing the Knowledge Base (One-Time Setup)
Before the system can answer questions, your documents need to be prepared. This is a one-time process (with periodic updates as documents change):
- Collect your documents — policies, FAQs, manuals, guides, and any other knowledge sources the AI should reference.
- Split and organize — documents are broken into smaller, meaningful sections, like creating a detailed index for a library.
- Build the knowledge base — these sections are stored in a smart, searchable format that allows the system to find relevant information in milliseconds.
Many RAG systems use an embedding model and semantic search to retrieve relevant information from internal documents, knowledge bases, and enterprise systems.
The Right Side: Retrieving Information and Generating a Grounded Response (Real-Time)
- User asks a question — an employee types something like “How many sick days can I take per year?”
- System finds relevant info — the system searches the knowledge base and retrieves the most relevant sections.
- AI generates a grounded answer — the AI receives both the question and the retrieved content, and crafts a response based on what it found.
- Sourced answer is delivered — the user gets their answer along with a reference to the source document.
Where RAG Is Used Today
RAG isn’t theoretical, it’s already delivering value across industries. Here are some of the most common applications:
Academic and Research Publishing
Publishers are using RAG to make vast research archives easier to navigate and more useful. Instead of relying on keyword searches, researchers can ask natural-language questions and receive precise, source-backed answers drawn directly from journal content and publications.
Education and Adaptive Learning
Educational institutions and EdTech platforms are using RAG-powered systems to deliver personalized learning experiences. Students can ask questions and receive responses grounded in approved course materials, improving accuracy, consistency, and learning outcomes.
Healthcare and Clinical Knowledge
Healthcare organizations are using RAG to provide clinicians with access to current medical guidelines, drug information, and regulatory updates. By retrieving information from trusted clinical sources, these systems help improve accuracy and support informed decision-making
Enterprise Knowledge Management
Organizations are deploying RAG systems internally to help employees quickly access policies, onboarding documents, operational procedures, and support resources. This reduces time spent searching for information and improves productivity across teams.
These systems are increasingly being used for enterprise question answering and customer service applications where fast access to accurate information is critical.
RAG vs Fine-Tuning: What’s the Difference?
If you’ve been evaluating AI solutions, you may have heard about “fine-tuning” as another way to customize AI. Here’s a simple comparison to help you understand the difference:
| RAG | Fine-Tuning | |
| Updating knowledge | Update the documents and you’re done | Requires retraining the model (expensive) |
| Cost | Lower, mainly storage and search infrastructure | Higher, requires specialized compute resources |
| Speed to deploy | Weeks | Months |
| Can show sources? | Yes, the AI can cite where it found the answer | No, the knowledge is baked into the model |
| Best suited for | Factual Q&A, knowledge bases, support bots | Changing the AI’s tone, style, or behavior |
| Risk of outdated info | Low, documents are always current | Higher, until the model is retrained |
For most business applications involving enterprise knowledge, support systems, and factual question answering, retrieval-augmented generation (RAG) is often the more practical starting point because it is faster to deploy, easier to maintain, and can work with continuously updated information.
In some advanced use cases, organizations combine RAG with fine-tuning to improve both factual accuracy and domain-specific behavior.
The Future of Retrieval-Augmented Generation
RAG has quickly become the go-to architecture for building AI systems that need to be accurate, current, and grounded in organizational knowledge. But technology continues to evolve rapidly:
- Smarter retrieval — AI systems are getting better at understanding the intent behind a question, not just the keywords. This means more relevant results and fewer misses, even when the exact terminology doesn’t match the source document.
- Multi-step reasoning — Next-generation RAG systems can plan complex research strategies, searching across multiple sources, cross-referencing information, and synthesizing answers from different documents rather than returning a list of links.
- Beyond text — RAG is expanding to work with images, charts, tables, and video content, enabling richer, more complete answers from content that goes beyond the written word.
- Domain-specific RAG — Generic retrieval models are giving way to purpose-built ones trained on domain-specific content, retrieving with substantially higher precision than a general-purpose model applied to the same material.
For organizations in publishing, education, and healthcare, these are not distant possibilities, they are the next wave of capability arriving in domains where content quality, retrieval precision, and accountability have always mattered most. The organizations that invest in RAG now will be best positioned to adopt these advances as they mature.
Authored by RadhaKrishna S P






